Web scraping has become an essential skill for extracting valuable data from the vast realms of the internet. As a proficient SEO and copywriter, I will guide you through the best websites to practice web scraping and the tools to enhance your scraping journey.
What is Web Scraping?

Web scraping automates the process of extracting large volumes of data from websites. Instead of manually copying information, web scrapers download the HTML code of a page and organize the data into a structured format.
Choosing Your Web Scraping Tools
Various tools are available for web scraping, each catering to different needs. Some popular options include scraping libraries like Requests, BeautifulSoup, and Cheerio, as well as frameworks like Scrapy and Selenium.
You can use ScrapingBee API and Smartproxy’s SERP API for custom solutions, while ready-made scraping tools like ParseHub and Octoparse are also widely used. Python stands out as the most favored programming language for data collection, with numerous Python-based web scrapers available.
Which Websites Allow Web Scraping?
While web scraping is legal, not all websites permit such activities due to the strain it puts on their servers. You can check a site’s policy regarding scraping by accessing “/robots.txt” after the URL.
Why Do You Need Proxies for Web Scraping?
Using proxies is essential to avoid IP blocks and throttling. A proxy server is an intermediary between you and the internet, masking your IP address and allowing access to geo-restricted content. Proxies are valid for high-volume data collection, where multiple connection requests are made daily.
Best Websites to Practice Web Scraping
1) Toscrape
Toscrape offers a web scraping sandbox suitable for beginners and advanced users. The website features a fictional bookstore with thousands of books to scrape, allowing you to practice basic data extraction such as titles, stock availability, prices, and authors using libraries like Requests and Beautiful Soup.
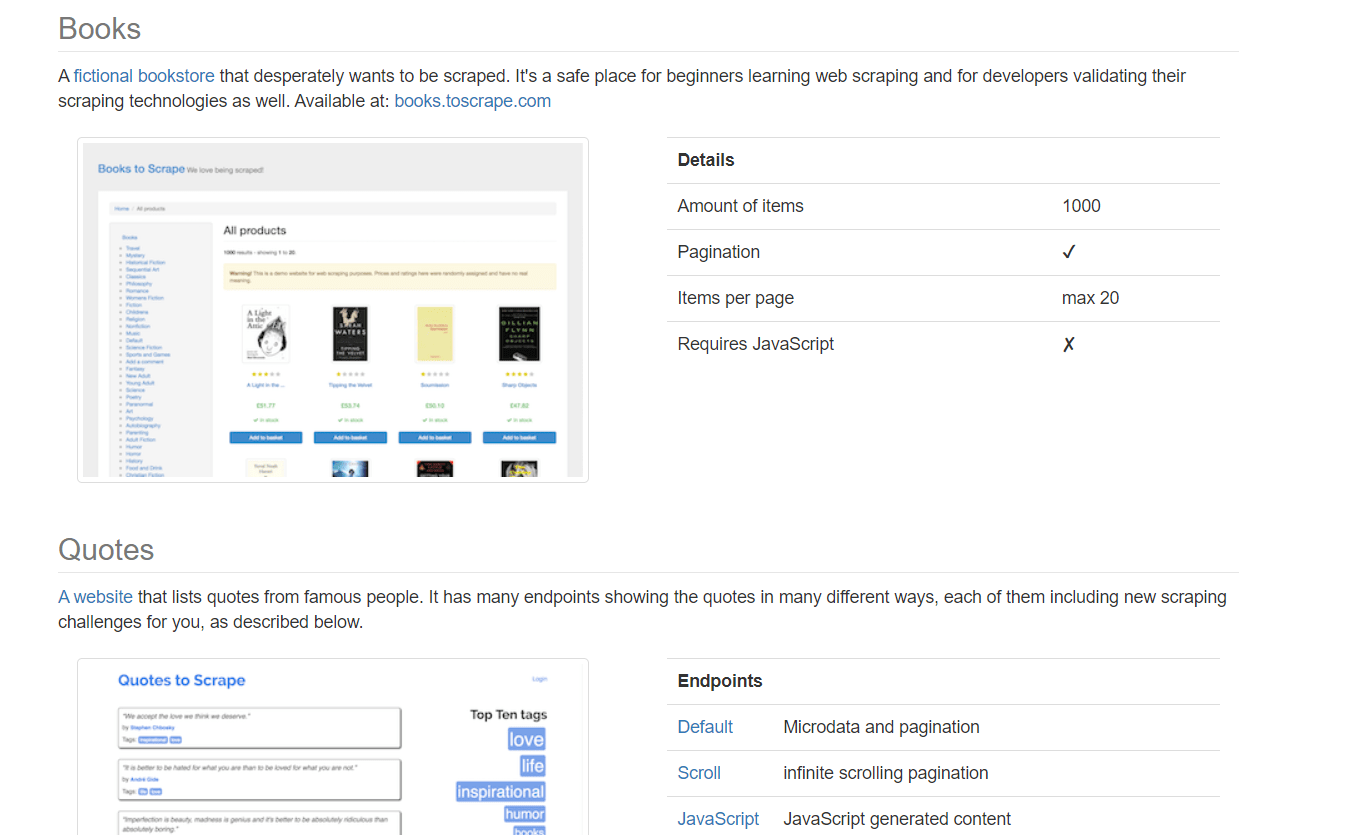
The second part of Toscrape provides quotes from famous individuals, presenting advanced challenges for scraping JavaScript-generated content with lazy loading and delayed rendering. This section may require a headless browser to complete the tasks.
2) Scrapethissite
Similar to Toscrape, Scrapethissite is an excellent sandbox for learning web scraping. For beginners, it allows the practice of static data collection using Python to scrape tables and titles. Advanced users can learn to scrape dynamically generated content based on JavaScript, honing their skills in handling logins, session cookies, CSRF tokens, and other challenges encountered in real-world scenarios.

3) Yahoo! Finance
Yahoo! Finance is an ideal platform for practicing web scraping in a real-world context. With its vast database of up-to-date financial records, you can extract stock and financial statement data, track price changes, and perform data analysis.
Structuring web data into CSV files or Excel Spreadsheets using Python is recommended for calculating stock returns.
4) Wikipedia
Wikipedia offers ample opportunities to practice scraping large amounts of readily available data in standard HTML. You can gain experience dealing with identifiers and properties within specific content units. Additionally, you can hone your skills by scraping tables, images, and graphs. However, be cautious of your scraping speed to avoid potential access blocks.
5) Reddit
Reddit is an excellent source for practicing web scraping on forums. You can extract comments, images, links, and other content with the highest upvotes, analyze recurring keywords in subreddits, and gauge public sentiment behind specific news.
It may even lead you to innovative business ideas. However, scraping Reddit’s redesigned website can be tricky; using the old layout at old.reddit.com is recommended.
FAQs
What is web scraping?
Web scraping is an automated process of extracting large amounts of data from websites. Instead of manually copying information, web scrapers download a web page’s HTML code and organize the data into a structured format for analysis.
What tools can I use for web scraping?
There are various tools available for web scraping. Some popular options include scraping libraries like Requests, BeautifulSoup, and Cheerio, as well as frameworks like Scrapy and Selenium. You can also use custom-built scrapers like ScrapingBee API and Smartproxy’s SERP API or ready-made scraping tools like ParseHub and Octoparse.
Which programming language is best for web scraping?
Python is widely considered the most popular programming language for web scraping. Most web scrapers are Python-based, offering a rich ecosystem of libraries and tools that make data collection efficient and effective.
Are all websites suitable for web scraping?
While web scraping is legal, not all websites allow scraping activities. Some websites may block web scrapers to protect their servers from excessive requests. Check a website’s “robots.txt” file to see if scraping is permitted.
Why do I need proxies for web scraping?
Proxies are essential for web scraping because they help you avoid IP blocks and throttling. A proxy server acts as an intermediary between you and the internet, masking your IP address and allowing you to access geo-restricted content.
To Sum Up – These websites offer valuable opportunities to sharpen your web scraping skills. Use the appropriate tools and residential proxies to ensure a seamless and successful web scraping journey. Happy scraping!
